AI Chip Architectures Race To The Edge
Nov 30, 2018
Companies battle it out to get artificial intelligence to the edge using various chip architectures as their weapons of choice.
As machine-learning apps start showing up in endpoint devices and along the network edge of the IoT, the accelerators that make AI possible may look more like FPGA and SoC modules than current data-center-bound chips from Intel or Nvidia.
Artificial intelligence and machine learning need powerful chips for computing answers (inference) from large data sets (training). Most AI chips—both training and inferencing—have been developed for data centers. This trend will soon shift, however. A large part of that processing will happen at the edge, at the edge of a networks or in or closer to sensors and sensor arrays.
Training almost certainly will stay in the cloud because the most efficient delivery of that big chunk of resources comes from the Nvidia GPUs, which dominate that part of the market. Although a data center may house the training portion—with its huge datasets—the inference may mostly end up on the edge. Market forecasts seem to agree on that point.
The market for inference hardware is new but changing rapidly, according to Aditya Kaul, research director at Tractica and author of its report on AI for edge devices. “There is some opportunity in the data center and will continue to be. They [the market for cloud-based data center AI chips] will continue to grow. But it’s at the edge, in inference, where things get interesting,” Kaul said. He says at least 70 specialty AI companies are working on some sort of chip-related AI technology.
“At the edge is where things are going to get interesting with smartphones, robots, drones, cameras, security cameras—all the devices that will need some sort of AI processing in them,” Kaul said.
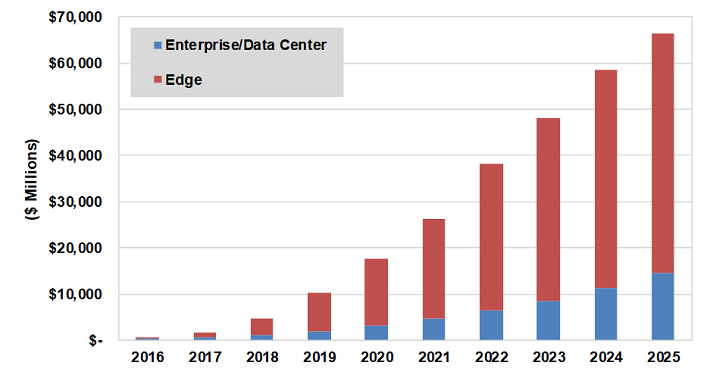
Fig.: Deep learning chipset revenue by market sector.
By 2025, cloud-based AI chipsets will account for $14.6 billion in revenue, while edge-based AI chipsets will bring in $51.6 billion—3.5X larger than in the data center, made up mostly of mobile phones, smart speakers, drones, AR/VR headsets and other devices that all need AI processing.
Although Nvidia and Intel may dominate the market for data-center-based machine learning apps now, who will own the AI market for edge computing—far away from the data center? And what will those chips look like?
What AI edge chips need to do
Edge computing, IoT and consumer endpoint devices, will need high-performance inference processing at relatively low cost in power, price and die size, according to Rich Wawrzyniak, ASIC and SoC analyst at Semico Research. That’s difficult, especially because most of the data that edge devices will process will be chunky video or audio data.
“There’s a lot of data, but if you have a surveillance camera, it has to be able to recognize the bad guys in real time, not send a picture to the cloud and wait to see if anyone recognizes him,” Wawrzyniak said.
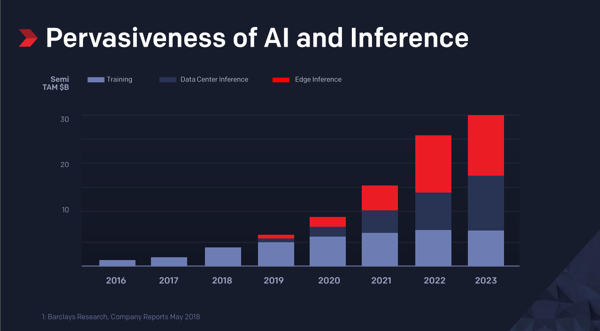
Some of the desire to add ML-level intelligence to edge devices comes from the need to keep data on those devices private, or to reduce the cost of sending it to the cloud. Most of the demand, however, comes from customers who want devices in edge-computing facilities or in the hands of their customers, rather than simply collecting the data and periodically sending it to the cloud so they can interact directly with the company’s own data or other customers and passers-by in real time.
“Customers realize they don’t want to pass a lot of processing up to the cloud, so they’re thinking the edge is the real target,” according to Markus Levy, head of AI technologies at NXP Semiconductors. “Now that you can do AI at the edge, you can turn the IoT into something with real capabilities. We see growth coming really fast between the consumer IoT and the industrial IoT Along with embedded, those are our biggest growth areas.”
Business technology customers surveyed this year by IDC said they are definitely moving machine learning to edge devices, primarily in cars, smart homes, video surveillance cameras and smartphones, according to Shane Rau, an analyst for IDC, whose customer survey named those four devices as the candidates for ML.
Architecture trends for AI edge
The range of requirements for edge computing could include billions of industrial and consumer devices, so it’s unlikely that any single architecture can satisfy them all.
It is possible to run inference models on microcontrollers and relatively low-end chips, but most machine-learning functions need a boost from one of what has become a long list of optional CPU add-ins based on FPGAs, ASICs and other SoC configurations, as well as combinations of GPUs, CPUs and occasionally by a special-purpose ASICS like Google’s Tensor Processing Unit, said NXP’s Levy.
Most of that help comes in the form of accelerators. These FPGAs, SoCs, ASIC and other special-purpose chips are designed to help resource-constrained, x86-based devices process large volumes of image or audio data through one layer after another of analytic criteria so the app can correctly calculate and weight the value of each.
Intel and Nvidia have made sallies toward the edge AI market. Efforts such as Nvidia’s Jetson—a GPU module platform with a 7.5W power budget that is a fraction of Nvidia’s more typical 70W but way too high for edge applications that tend not to rise above 5W—have not been convincing, Kaul said.
“There are a lot of IP companies are accelerating for neural networks, so there are enough options that accelerators are starting to become a requirement for inference in edge devices,” Levy said.
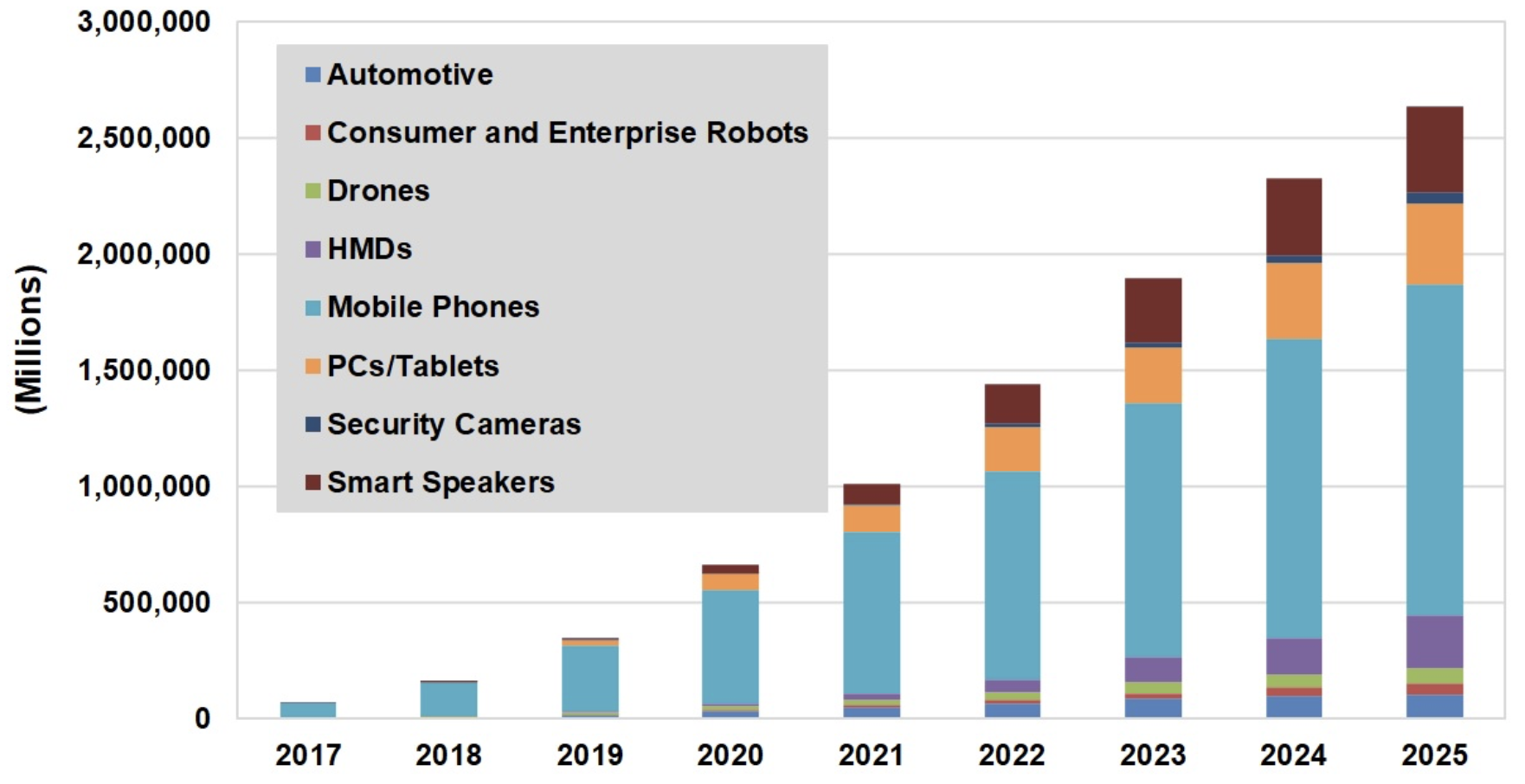
Fig.: AI edge device shipments by category.
But adding ML acceleration and support to potentially billions of devices will take more customizability, lower costs and specifications tailored more specifically to the needs of ML apps on resource-constrained devices—meaning the whole market will need much better processors if it’s going to succeed.
Neural inferencing requires trillions of multiply-accumulate steps as the model pulls data from one layer of its matrix of formulas, although each layer may require different data sizes, and some of these devices may run faster with inputs set for 8-bit integers rather than 16.
“To get good throughput in a data center, most architectures rely on the dozens or hundreds of tasks that have to use the same set of weights to create batches,” according to Geoff Tate, co-founder and CEO Flex Logix. “If you have 28 images, you load the images, load the weights for the first stage, do the math for the first stage, save the result, and then load the weights for the second stage. By doing all 28 batches on each layer you reduce the amount of weight-loading time to 1/28 what it would be if you did it one at a time. If loading and managing weights is what you’re not good at, you get around it by batching. That’s why you’ll see benchmarks that show batch 28 running at a lower efficiency than batch 1. If you are slow to load weights, it’s harder to scale. But that’s exactly how you have to do it anywhere outside the data center. If you have a surveillance camera, you have to process the images as they come in, so that batch size always equals 1. If you’re measuring performance, batch size always equals 1 outside the data center.
A neural networking engine Flex Logix is developing avoids the batching issues. “Because we load weights so quickly, we don’t need to do batching, so our performance is the same at batch 1 as it is at 28, which is hugely important in edge applications,” said Tate.
Two new efforts at inference hardware
Xilinx has tried to capitalize on its experience in FPGAs and in systems-level design with a new product line and roadmap designed to address as many parts of the edge/device market as possible.
The company discussed the idea last spring but only announced it formally October, describing an Adaptive Compute Acceleration Platform that “draws on the strength of CPUs, GPUs and FPGAs to accelerate any application.”
Xilinx presentations describe a broad product line, list of use cases and details about its AI engine core, the goal for which is to deliver three to eight times the performance per silicon area than traditional approaches and provide high-performance DSP capabilities.
Flex Logix, meanwhile, has created a reconfigurable neural accelerator that uses low DRAM bandwidth. The target spec for silicon area and power is due during the first half of next year, with tape-out in the second half of the year. The inferencing engine will act as a CPU, not simply a larger, fancier accelerator. It offers a modular, scalable architecture intended to reduce the cost in time and energy of moving data by reducing the need to move it and by improving the way data and matrix calculations load to reduce bottlenecks.
The chip dedicates DRAM as if it were dedicated to a single processor block rather than managing it as one big pool of memory. The DRAM does not feed data to several parts of the chip simultaneously. “Treating DRAM, which is really expensive, as one big pool of memory flowing into one processor block is typical of Van Neumann architecture, but isn’t going to be the winning architecture for neural nets,” Tate said.
Early days
The rush of Xilinx, Flex Logix and other companies to a still-developing market for inference at the edge shows broad confidence in both the market and the ability of SoC and FPGA makers to deliver good technology to deal with them, Wawrzyniak said, but it’s no guarantee they’ll be able to overcome issues like security, privacy, the inertia of the status quo and other intangibles, he said. Again, the market for ML-accelerating FPGAs, ASICs and SoCs is still in its infancy.
It’s normal to see a lot of new players and new approaches when a new market develops, according to Linley Gwennap of The Linley Group. FPGA and ASIC vendors are in the mix because those technologies allow a company that knows what it’s doing to produce a reasonable product quickly. Standards will eventually return within a year or two, however, which will stabilize the number and specialties of the players involved and ensure interoperability with the rest of the market, he said.
Source: SemiEngineering